druidというリアルタイムデータ分析ツールを知った
κeenです。社内ハッカソンに出てきた。そこでdruidというツール(?)を触ったのでそれについて。
読み方は「ドゥルイド」でいいのかな?公式ページはこちら。Metamarketsが主導で開発しているようで、オープンソースになっている。
公式サイトを少し回遊してもらうと分かると思うが、時系列データを分散環境でストリーミング処理出来るツール。分散環境で動くだけあってコンポーネントはいくつかある。
主にはストリーミングデータを取り込む「REALTIME」、クライアントからのクエリを処理する「BROKER」、過去のデータを処理する「HISTORICAL」があるようだ。 BROKERがDEEP STORAGE(s3などの永続データストア)にデータを保存し、HISTORICALがオンデマンドにそのデータを読み出してBROKERに返す。
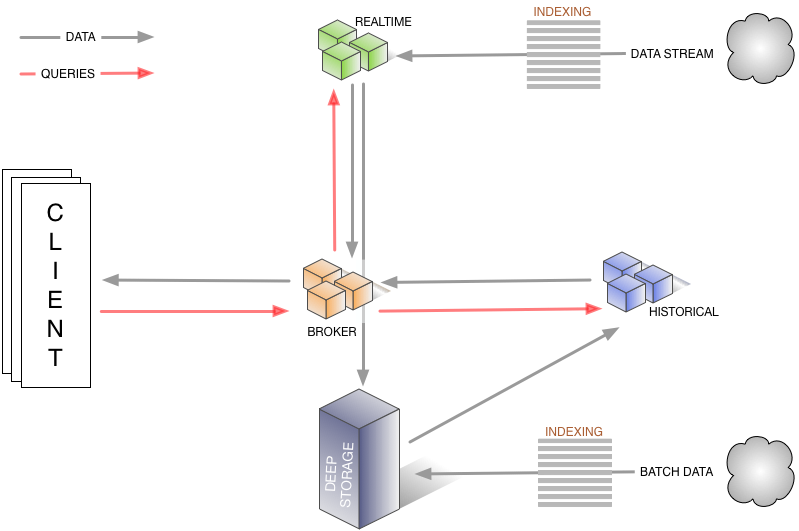
イメージとしてはこんな感じだが、実際に動かすのには他のコンポーネントも必要で、分散環境に必須なZookeeperが必要なのはもちろんのこと、全体を司る「COORDINATOR」、取り込んだデータのメタデータを保存する「METADATA STORAGE」も必要になる。
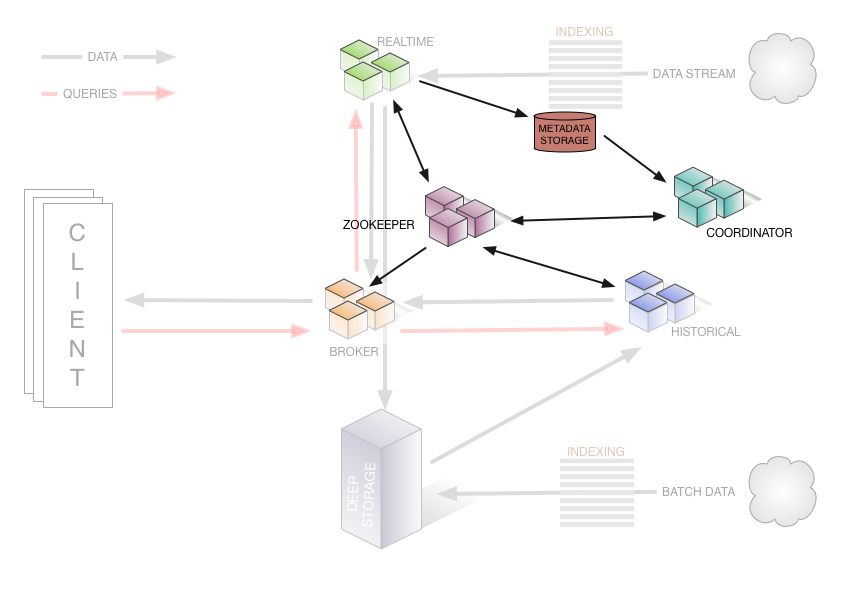
画像の出展はこちら。
中々に大仰なアーキテクチャだがどのみちリアルタイムデータ分析基盤を作ろうと思うとこれくらい必要になる。それを1まとめにしてディストリビュートしてくれるdruidを使った方がなんぼか近道な気はする。
さて、これを1インスタンスで動かそうと思うと、DEEP STORAGEはローカルファイルシステム、METADATA STORAGEは組込みのDerby DBでまかなえ、REALTIMEはデータを取り込む時にのみ必要なのでZookeeper、Coordinator、Broker、Historical、都合4つのJava製ミドルウェアを起動すればどうにか使える。 これら合わせても2GBくらいのメモリしか必要なかったので十分手元で動く。
さて、このDruid、どういうことが出来るかというとクエリに注目すれば「Group By付きのAggrigation Functionを高速に動かす」が主な目的だろうか。他にも色々あるが。 BIツールや他のダッシュボードツールなんかと連携してストリーミングデータをリアルタイムに可視化するのに一役買う。YahooやAlibabaなんかでも使われているようだ。 例えばDruidをサポートするダッシュボードツール、panoramixなんかもある。
今回のハッカソンはGCPがテーマで、Cloud Pub/Subからデータを取り込むことになったがDruidにはPub/Subからデータを取り込むREALTIMEがない。ということでハッカソンでPub/Sub extensionを作った。 メーリスに投稿して様子を覘った上でコードを整理してプルリクを出す予定だ。 拡張は思ったよりも作りやすく、ドキュメントを読まなくても既存のKafka拡張を参考にするだけで書けた。まあ、その後苦労したが。
はじめて使うDBのプラグイン書いたらデータのロードは出来たもののクエリの投げ方が分からずに入ったデータを確認出来ない…っ…
— κeen (@blackenedgold) 2016年2月26日
今回作ったのはFirehose Pluginと呼ばれるものだが、他にもプラグインの種類は色々あるみたいだ。 しかしFirehose Pluginの基底クラスはあまりストリーミングデータのインポートには良くない気がする。FirehoseV2というのがあって、それが良いインターフェースになっていたが使い方が分からなかった。
今が0.9.0-SNAPSHOT。1.0.0が出る頃が楽しみだ。